일변량 양적 자료를 활용해 만드는 다양한 그래프

양적 자료는 크기 비교가 가능해 질적 자료 대비 분석 방법이 다양하다.

평균(Mean)
개별 값들의 합계를 그 개별 값들의 개수로 나누는 것
ex) 균형점, 무게중심
절사평균(Trimmed Mean)
표본중에서 작은값n%와 큰값 n%를 제외하고
나머지(100-2n)%의 자료만 사용하여 구한 평균
극단적인 값에 의한 오차를 줄이기 위해 사용

자료가 정규분포를 이루면 평균이 의미가 있으나
어느 한쪽으로 치우친 경우 평균 보다는 중앙값을 대표값으로 사용할 수 있음
4분위수
3개의 수로 데이터를 추정
나열한 것을 4등분 함
등분점 3개


mydata=c(50,60,100,75,200)
mydata.big<-c(mydata, 50000)
mean(mydata)
mean(mydata.big)
median(mydata)
median(mydata.big)
mean(mydata,trim=0.2)
mean(mydata.big, trim=0.2)
quantile(mydata)
quantile(mydata, (0:10)/10)
quantile(mydata.big)
summary(mydata)
fivenum(mydata)
fivenum(mydata.big)
산포(Distribution)
데이터가 퍼져 있는 정도, 흩어져 있는 정도
분산과 표준편차를 이용함

range(mydata)
diff(range(mydata))
var(mydata)
sd(mydata)
박스 상자 (box plot)
일변량 양적 자료의 데이터를 시각적으로 확인 할 수 있는 도구



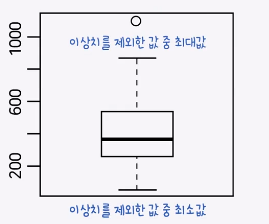



head(state.x77)
st.income<-state.x77[,"Income"]
boxplot(st.income, ylab="Income value")



boxplot(iris$Petal.Width,ylab="Petal.Width")
boxplot(Petal.Width~Species,data=iris,ylab="Petal.Width")

히스토그램
실수형 자료에 사용
ex) 셀수 없는 자료: 키, 몸무게 등의 소수점
>> 구간을 나누어 표시할 것
막대그래프와 히스토그램의 차이


hist(st.income,
main="Histogram for Income",
xlab="income",
ylab="frequency",
border="blue",
col="green",
las=2, #X축글씨방향(0~3)
breaks=5)

줄기-잎-그림
시각적 이해를 돕고자 사용함
각 점수대 별로 몇 명인지 알 수 있음
막대그래프를 눕혀 놓은 형태
Scale 값에 따라 줄기 잎의 크기가 변함

score<-c(40,55,90,75,59,60,63,65,69,71)
stem(score, scale=2)

※위 자료는 K-MOOC 단국대학교 오세종 교수님의 R 데이터 분석 입문을 참고하였습니다.
'공부와 공부와 공부 > R' 카테고리의 다른 글
| 5-1 다변량 자료의 탐색 - 산점도 plot(), pch(), pairs() (0) | 2019.05.12 |
|---|---|
| 4-4 문자열 함수 Paste(), Substr(), nchar(), gstr() (0) | 2019.05.12 |
| R 그래프를 만드는 데 뜨는 에러 Error in RStudioGD() (0) | 2019.05.08 |
| 4-2 R을 이용해 막대그래프와 파이그래프 만들기 table(), barplot(), par(), pie() (0) | 2019.05.07 |
| 4-1 기초 통계 개념 (0) | 2019.05.06 |


